 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Pixel Correspondence Estimation
Papers and Code
VisuoTactile 6D Pose Estimation of an In-Hand Object using Vision and Tactile Sensor Data
Jan 04, 2026Knowledge of the 6D pose of an object can benefit in-hand object manipulation. In-hand 6D object pose estimation is challenging because of heavy occlusion produced by the robot's grippers, which can have an adverse effect on methods that rely on vision data only. Many robots are equipped with tactile sensors at their fingertips that could be used to complement vision data. In this paper, we present a method that uses both tactile and vision data to estimate the pose of an object grasped in a robot's hand. To address challenges like lack of standard representation for tactile data and sensor fusion, we propose the use of point clouds to represent object surfaces in contact with the tactile sensor and present a network architecture based on pixel-wise dense fusion. We also extend NVIDIA's Deep Learning Dataset Synthesizer to produce synthetic photo-realistic vision data and corresponding tactile point clouds. Results suggest that using tactile data in addition to vision data improves the 6D pose estimate, and our network generalizes successfully from synthetic training to real physical robots.
* Accepted for publication in IEEE Robotics and Automation Letters (RA-L), January 2022. Presented at ICRA 2022. This is the author's version of the manuscript
DiffRegCD: Integrated Registration and Change Detection with Diffusion Features
Nov 12, 2025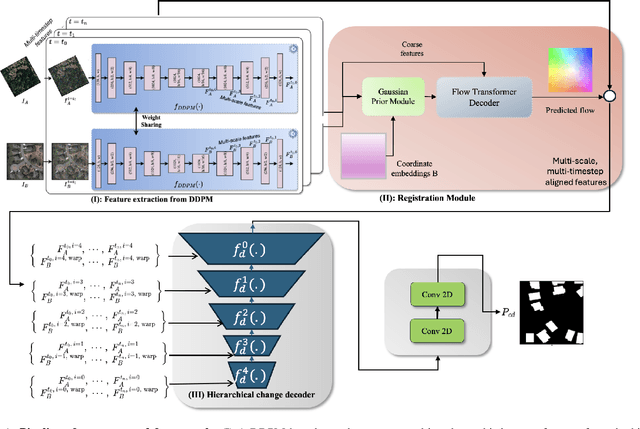

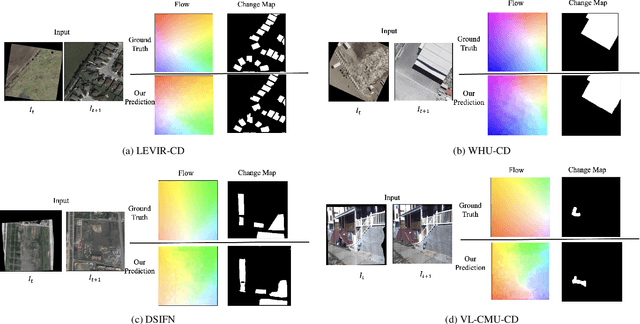

Change detection (CD) is fundamental to computer vision and remote sensing, supporting applications in environmental monitoring, disaster response, and urban development. Most CD models assume co-registered inputs, yet real-world imagery often exhibits parallax, viewpoint shifts, and long temporal gaps that cause severe misalignment. Traditional two stage methods that first register and then detect, as well as recent joint frameworks (e.g., BiFA, ChangeRD), still struggle under large displacements, relying on regression only flow, global homographies, or synthetic perturbations. We present DiffRegCD, an integrated framework that unifies dense registration and change detection in a single model. DiffRegCD reformulates correspondence estimation as a Gaussian smoothed classification task, achieving sub-pixel accuracy and stable training. It leverages frozen multi-scale features from a pretrained denoising diffusion model, ensuring robustness to illumination and viewpoint variation. Supervision is provided through controlled affine perturbations applied to standard CD datasets, yielding paired ground truth for both flow and change detection without pseudo labels. Extensive experiments on aerial (LEVIR-CD, DSIFN-CD, WHU-CD, SYSU-CD) and ground level (VL-CMU-CD) datasets show that DiffRegCD consistently surpasses recent baselines and remains reliable under wide temporal and geometric variation, establishing diffusion features and classification based correspondence as a strong foundation for unified change detection.
PADReg: Physics-Aware Deformable Registration Guided by Contact Force for Ultrasound Sequences
Aug 12, 2025Ultrasound deformable registration estimates spatial transformations between pairs of deformed ultrasound images, which is crucial for capturing biomechanical properties and enhancing diagnostic accuracy in diseases such as thyroid nodules and breast cancer. However, ultrasound deformable registration remains highly challenging, especially under large deformation. The inherently low contrast, heavy noise and ambiguous tissue boundaries in ultrasound images severely hinder reliable feature extraction and correspondence matching. Existing methods often suffer from poor anatomical alignment and lack physical interpretability. To address the problem, we propose PADReg, a physics-aware deformable registration framework guided by contact force. PADReg leverages synchronized contact force measured by robotic ultrasound systems as a physical prior to constrain the registration. Specifically, instead of directly predicting deformation fields, we first construct a pixel-wise stiffness map utilizing the multi-modal information from contact force and ultrasound images. The stiffness map is then combined with force data to estimate a dense deformation field, through a lightweight physics-aware module inspired by Hooke's law. This design enables PADReg to achieve physically plausible registration with better anatomical alignment than previous methods relying solely on image similarity. Experiments on in-vivo datasets demonstrate that it attains a HD95 of 12.90, which is 21.34\% better than state-of-the-art methods. The source code is available at https://github.com/evelynskip/PADReg.
AllTracker: Efficient Dense Point Tracking at High Resolution
Jun 08, 2025We introduce AllTracker: a model that estimates long-range point tracks by way of estimating the flow field between a query frame and every other frame of a video. Unlike existing point tracking methods, our approach delivers high-resolution and dense (all-pixel) correspondence fields, which can be visualized as flow maps. Unlike existing optical flow methods, our approach corresponds one frame to hundreds of subsequent frames, rather than just the next frame. We develop a new architecture for this task, blending techniques from existing work in optical flow and point tracking: the model performs iterative inference on low-resolution grids of correspondence estimates, propagating information spatially via 2D convolution layers, and propagating information temporally via pixel-aligned attention layers. The model is fast and parameter-efficient (16 million parameters), and delivers state-of-the-art point tracking accuracy at high resolution (i.e., tracking 768x1024 pixels, on a 40G GPU). A benefit of our design is that we can train on a wider set of datasets, and we find that doing so is crucial for top performance. We provide an extensive ablation study on our architecture details and training recipe, making it clear which details matter most. Our code and model weights are available at https://alltracker.github.io .
UFM: A Simple Path towards Unified Dense Correspondence with Flow
Jun 10, 2025Dense image correspondence is central to many applications, such as visual odometry, 3D reconstruction, object association, and re-identification. Historically, dense correspondence has been tackled separately for wide-baseline scenarios and optical flow estimation, despite the common goal of matching content between two images. In this paper, we develop a Unified Flow & Matching model (UFM), which is trained on unified data for pixels that are co-visible in both source and target images. UFM uses a simple, generic transformer architecture that directly regresses the (u,v) flow. It is easier to train and more accurate for large flows compared to the typical coarse-to-fine cost volumes in prior work. UFM is 28% more accurate than state-of-the-art flow methods (Unimatch), while also having 62% less error and 6.7x faster than dense wide-baseline matchers (RoMa). UFM is the first to demonstrate that unified training can outperform specialized approaches across both domains. This result enables fast, general-purpose correspondence and opens new directions for multi-modal, long-range, and real-time correspondence tasks.
Homeomorphism Prior for False Positive and Negative Problem in Medical Image Dense Contrastive Representation Learning
Feb 07, 2025Dense contrastive representation learning (DCRL) has greatly improved the learning efficiency for image-dense prediction tasks, showing its great potential to reduce the large costs of medical image collection and dense annotation. However, the properties of medical images make unreliable correspondence discovery, bringing an open problem of large-scale false positive and negative (FP&N) pairs in DCRL. In this paper, we propose GEoMetric vIsual deNse sImilarity (GEMINI) learning which embeds the homeomorphism prior to DCRL and enables a reliable correspondence discovery for effective dense contrast. We propose a deformable homeomorphism learning (DHL) which models the homeomorphism of medical images and learns to estimate a deformable mapping to predict the pixels' correspondence under topological preservation. It effectively reduces the searching space of pairing and drives an implicit and soft learning of negative pairs via a gradient. We also propose a geometric semantic similarity (GSS) which extracts semantic information in features to measure the alignment degree for the correspondence learning. It will promote the learning efficiency and performance of deformation, constructing positive pairs reliably. We implement two practical variants on two typical representation learning tasks in our experiments. Our promising results on seven datasets which outperform the existing methods show our great superiority. We will release our code on a companion link: https://github.com/YutingHe-list/GEMINI.
ForestVO: Enhancing Visual Odometry in Forest Environments through ForestGlue
Apr 02, 2025Recent advancements in visual odometry systems have improved autonomous navigation; however, challenges persist in complex environments like forests, where dense foliage, variable lighting, and repetitive textures compromise feature correspondence accuracy. To address these challenges, we introduce ForestGlue, enhancing the SuperPoint feature detector through four configurations - grayscale, RGB, RGB-D, and stereo-vision - optimised for various sensing modalities. For feature matching, we employ LightGlue or SuperGlue, retrained with synthetic forest data. ForestGlue achieves comparable pose estimation accuracy to baseline models but requires only 512 keypoints - just 25% of the baseline's 2048 - to reach an LO-RANSAC AUC score of 0.745 at a 10{\deg} threshold. With only a quarter of keypoints needed, ForestGlue significantly reduces computational overhead, demonstrating effectiveness in dynamic forest environments, and making it suitable for real-time deployment on resource-constrained platforms. By combining ForestGlue with a transformer-based pose estimation model, we propose ForestVO, which estimates relative camera poses using matched 2D pixel coordinates between frames. On challenging TartanAir forest sequences, ForestVO achieves an average relative pose error (RPE) of 1.09 m and a kitti_score of 2.33%, outperforming direct-based methods like DSO by 40% in dynamic scenes. Despite using only 10% of the dataset for training, ForestVO maintains competitive performance with TartanVO while being a significantly lighter model. This work establishes an end-to-end deep learning pipeline specifically tailored for visual odometry in forested environments, leveraging forest-specific training data to optimise feature correspondence and pose estimation, thereby enhancing the accuracy and robustness of autonomous navigation systems.
SatDepth: A Novel Dataset for Satellite Image Matching
Mar 17, 2025



Recent advances in deep-learning based methods for image matching have demonstrated their superiority over traditional algorithms, enabling correspondence estimation in challenging scenes with significant differences in viewing angles, illumination and weather conditions. However, the existing datasets, learning frameworks, and evaluation metrics for the deep-learning based methods are limited to ground-based images recorded with pinhole cameras and have not been explored for satellite images. In this paper, we present ``SatDepth'', a novel dataset that provides dense ground-truth correspondences for training image matching frameworks meant specifically for satellite images. Satellites capture images from various viewing angles and tracks through multiple revisits over a region. To manage this variability, we propose a dataset balancing strategy through a novel image rotation augmentation procedure. This procedure allows for the discovery of corresponding pixels even in the presence of large rotational differences between the images. We benchmark four existing image matching frameworks using our dataset and carry out an ablation study that confirms that the models trained with our dataset with rotation augmentation outperform (up to 40% increase in precision) the models trained with other datasets, especially when there exist large rotational differences between the images.
Learning Inverse Laplacian Pyramid for Progressive Depth Completion
Feb 11, 2025Depth completion endeavors to reconstruct a dense depth map from sparse depth measurements, leveraging the information provided by a corresponding color image. Existing approaches mostly hinge on single-scale propagation strategies that iteratively ameliorate initial coarse depth estimates through pixel-level message passing. Despite their commendable outcomes, these techniques are frequently hampered by computational inefficiencies and a limited grasp of scene context. To circumvent these challenges, we introduce LP-Net, an innovative framework that implements a multi-scale, progressive prediction paradigm based on Laplacian Pyramid decomposition. Diverging from propagation-based approaches, LP-Net initiates with a rudimentary, low-resolution depth prediction to encapsulate the global scene context, subsequently refining this through successive upsampling and the reinstatement of high-frequency details at incremental scales. We have developed two novel modules to bolster this strategy: 1) the Multi-path Feature Pyramid module, which segregates feature maps into discrete pathways, employing multi-scale transformations to amalgamate comprehensive spatial information, and 2) the Selective Depth Filtering module, which dynamically learns to apply both smoothness and sharpness filters to judiciously mitigate noise while accentuating intricate details. By integrating these advancements, LP-Net not only secures state-of-the-art (SOTA) performance across both outdoor and indoor benchmarks such as KITTI, NYUv2, and TOFDC, but also demonstrates superior computational efficiency. At the time of submission, LP-Net ranks 1st among all peer-reviewed methods on the official KITTI leaderboard.
Multi-Camera Multi-Person Association using Transformer-Based Dense Pixel Correspondence Estimation and Detection-Based Masking
Aug 17, 2024

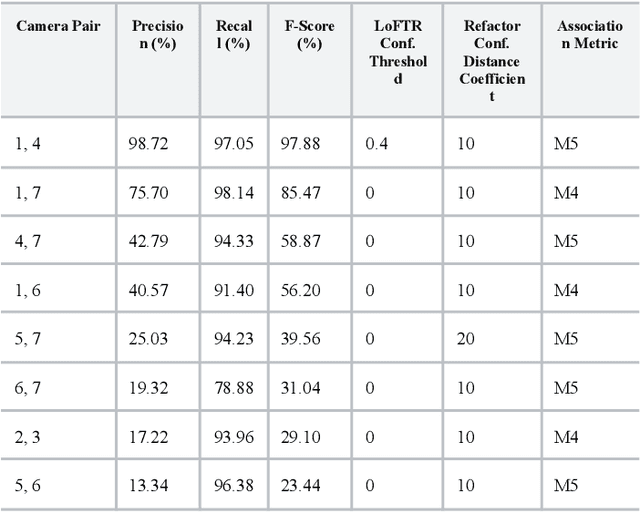

Multi-camera Association (MCA) is the task of identifying objects and individuals across camera views and is an active research topic, given its numerous applications across robotics, surveillance, and agriculture. We investigate a novel multi-camera multi-target association algorithm based on dense pixel correspondence estimation with a Transformer-based architecture and underlying detection-based masking. After the algorithm generates a set of corresponding keypoints and their respective confidence levels between every pair of detections in the camera views are computed, an affinity matrix is determined containing the probabilities of matches between each pair. Finally, the Hungarian algorithm is applied to generate an optimal assignment matrix with all the predicted associations between the camera views. Our method is evaluated on the WILDTRACK Seven-Camera HD Dataset, a high-resolution dataset containing footage of walking pedestrians as well as precise annotations and camera calibrations. Our results conclude that the algorithm performs exceptionally well associating pedestrians on camera pairs that are positioned close to each other and observe the scene from similar perspectives. On camera pairs with orientations that are drastically different in distance or angle, there is still significant room for improvement.